

Data Science 101 : Life Cycle of a Data Science Project



The first time I heard the word data science was in the university when my mentors — Professor Francisca Oladipo and Dayo Akinbami, took a course titled “Introduction to Data Science”.
Before getting into the university, I didn’t know what career path to choose in Computer Science (as I had several options in mind). But, I’m glad I took that introductory data science course. The least I can say is that it motivated me to find a better path and start a data science career, and I’m thankful for how far I’ve gone.
Although I'm not the subject matter for this article, I think it's good you understand how I got into data science. I wish to also use my story to motivate you that if I could come this far, you can do more. Mind you, I'm just starting, and my vision is to become a world-class data professional (by all standards) in the next few years.
My primary aim for writing this article is to demystify the word "data science", helping both individuals and enterprises to understand what it means and the different stages involved in building data science models. In subsequent articles, I'll discuss data science-based roles and the skills you need to become a top-notch data scientist.
I know that we mustn't all become data scientists. However, my joy will be complete if this article helps at least a single person to find the right foot into data science, just as the introduction to data science course inspired me to get started.
Let's get into this together.
What is Data Science?
The term "Data Science" is one of the most common buzzwords that you can find on the internet today, but it tends to be a difficult concept to grasp. If you ask three experts to explain what Data Science means, you're most likely to get four different definitions.
For the purpose of this article, I prefer to stick to this definition:
"Data Science is a multidisciplinary field of study that combines programming skills, domain expertise and knowledge of statistics and mathematics to extract useful insights and knowledge from data". Those who practice data science are called "data scientists". They combine a wide range of skills and modern technologies to analyze data collected from sensors, customers, smartphones, the web and other sources.
Let's break it down a little bit. Do you remember those times when you browse a product on an eCommerce platform, and you eventually see a strip of related products placed underneath the product details with the headline "customers who bought this item also bought ..." or "frequently bought together"? That's a good data science technique used by large retailers like Amazon to uncover the association between items and cross-sell to new and existing customers.
I like to think that data science is one of the most exciting fields in existence today, and there are so many reasons why it has become a buzzword in nearly every industry or niche. One of the major contributors is that every organization is sitting on a treasure trove of data that can provide transformative benefits. The second reason is that data science is a transformative and invaluable technology that fuels the digital economy, just as oil fueled the industrial economy.
When done correctly, data science produces valuable insights and reveals trends that enterprises can leverage to plan strategically, optimize business processes, make better-informed decisions, create more innovative services and products and more. A typical data science lifecycle comprises several stages. In the next section, I'll show you the different phases and what each stage involves.
Data Science Project Life Cycle
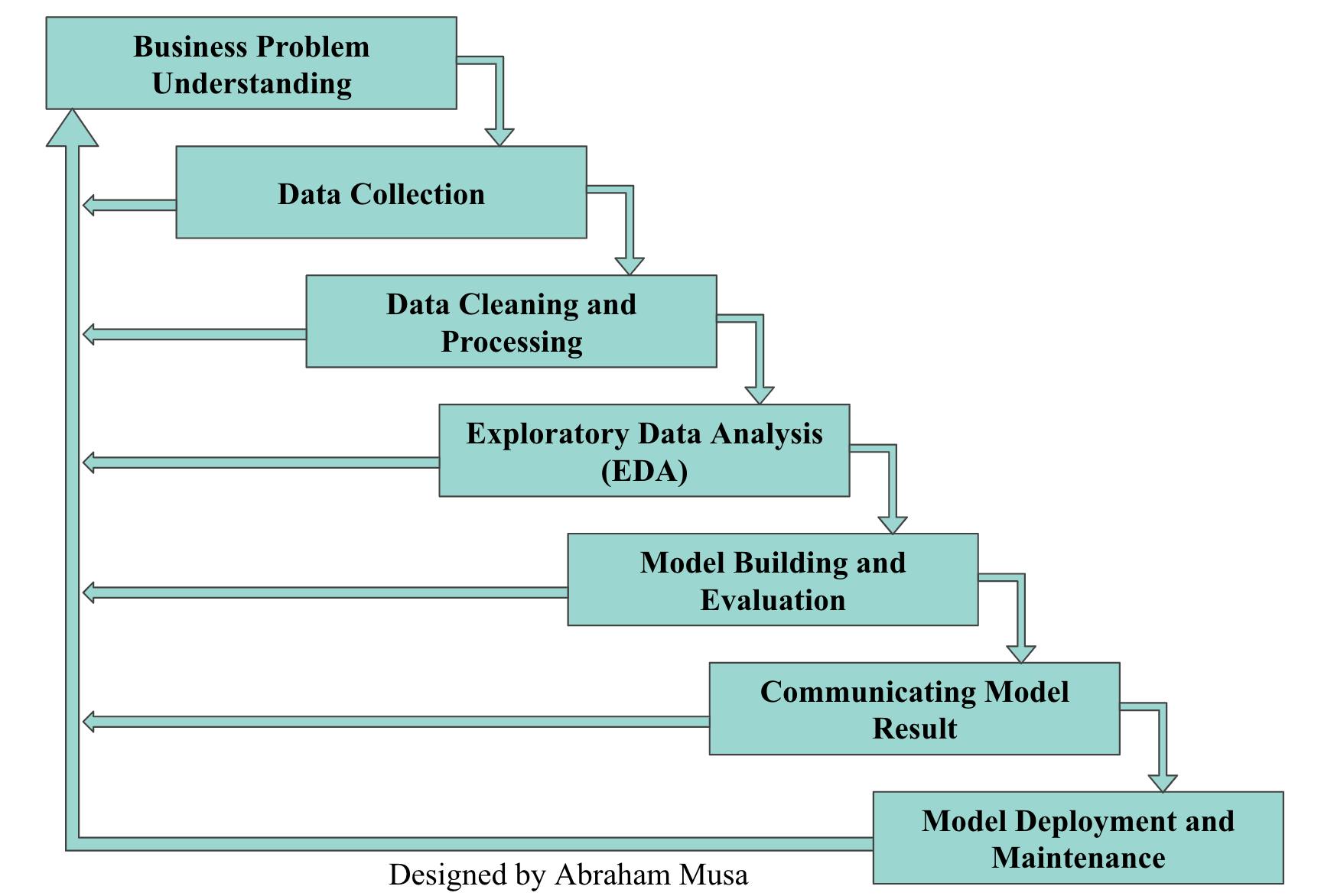
Many organizations and individuals talk about data science projects and products, but only a handful understand the steps involved in building a data science product or model. One thing I've come to discover so far is that only a few organizations have the appropriate infrastructure for data science. The majority of modern enterprises need to undergo significant transformations to benefit from data science.
In the remaining section of this post, I'll discuss the different steps you need to build a data science model or product. Every organization can adopt the methodology, regardless of their niche or size.
Business Problem Understanding
The first thing you have to do before you start collecting data and building a machine learning model is defining and understanding the problem you're trying to solve. You need to be able to transform the business needs into data science questions and actionable steps. A good way to approach this is by engaging with the right people whose business or process you want to improve or optimize and asking the appropriate questions.
I believe that data science products or models shouldn't exist in isolation. Instead, they should help enterprises transform existing business operations, improve business processes, or identify the causes and possible solutions to bad customer reviews and poor sales, e.t.c. So, it's helpful to truly understand the business problem and evaluate whether you can solve it using data science. That's because not all business problems can be solved using data science. A better understanding of the business problem increases your chances of building great data-driven products that can positively impact an organization.
Data Collection
The next step after problem understanding is to collect the right set of data. Data collection is essential, and it's practically challenging or (nearly impossible) to build a good model without quality data or the mechanism to collect the data.
Based on my research and interactions with several data science professionals, I can say categorically that many organizations collect unreliable, incomplete data and everything they do afterwards is messed up. Some organizations don't even know what kind of data to collect or where the data resides.
I believe that the data to collect depends on the business problem you're trying to solve. For instance, the perfect data for customer credit risk analysis should typically include demographics data, loan information and repayment data, transaction statements or telecom data. It'll be rather improper to collect data on customer height, shoe size, or trouser length for this same problem.
With the emergence of modern technologies like web scraping, cloud data collection tools and web APIs; database systems like MongoDB, PostgreSQL and MySQL; and tools like SQL, Python, R, Beautiful Soup, Scrapy, Spark, Apache, e.t.c, you can extract valuable data from anywhere at any time.
Data Cleaning and Processing
It's not enough to collect raw data without processing it. Just like pure gold, raw data is hardly usable and useless in its pure form. After collecting the appropriate dataset, you need to adequately clean and process the data before proceeding to the next step. In an ideal world, you're more likely to collect unstructured, irrelevant and unfiltered data. If you proceed to build an ML model without data processing and cleaning, your analysis results will definitely not make any sense. It's that simple: bad data produces terrible models, no matter how much you tune parameters or optimize your model's hyperparameters. To a great extent, the accuracy and effectiveness of your analysis highly depend on the quality of your data.
Working as a data scientist, I've encountered several forms of data problems, including duplicate and null values, inconsistent data types, missing data, invalid entries, improper formatting e.t.c that I had to resolve before proceeding.
It's important to note that most data scientists' time is spent on data collection, cleaning and processing. Some data professionals even argue it takes 80% of the time dedicated to a data project. If you want to build great data science models, you need to find and resolve flaws and inconsistencies in the dataset. Although data cleaning is painful and cumbersome, you'll get through and benefit from it as long as you remain focused on the final goal.
Exploratory Data Analysis (EDA)
At this point, you have a wealth of data. You've been able to clean and process the data to be as organized as possible. It's time to deeply inspect all the data features, data properties, build confidence in the data, gain intuition about the data, conduct a sanity check, figure out how to handle each feature. e.t.c This entire process is referred to as exploratory data analysis (EDA) - one of the common words in data science.
EDA involves several forms of analysis, including univariate analysis, bivariate analysis, missing values treatment, outlier treatment, variable transformation, feature engineering and correlation analysis. An effective EDA strategy provides the proper foundation that you need to create better, highly predictive and stable predictors from your original feature set.
One of the reasons I like EDA is that it helps me to ask the data several questions, better explore and visualize different datasets to identify patterns and uncover valuable insights useful in the subsequent steps of the ML lifecycle. It also exposes me to think innovatively and analytically.
Model Building and Evaluation
The model build and evaluation phase is where you do the actual modelling of the data. In fact, a lot of data scientists believe that the "real magic happens" at this phase. The first thing you have to do at this stage is to split the cleaned dataset from the previous step into train and test sets.
You should use the training set to build predictive models and evaluate your model's performance on the unseen data points (test set). ML problems are generally classified as either supervised or unsupervised. Supervised learning involves building a model that can accurately predict the target variable using a set of features known as predictors. While unsupervised learning is a self-learning approach where the model has to find all kinds of unknown patterns and relationships between all predictors.
You can use several evaluation metrics to examine how well your model works, and the choice of metrics to use depends on the kind of problem you're trying to solve. I won't bug you with those technical machine learning terms. Maybe, I'll write an article on some common evaluation metrics for supervised and unsupervised problems soon.
Based on the evaluation results, you may need to tweak the model's parameters to ensure that it generalizes well and can work well when exposed to previously unseen data. This process is known as hyperparameter tuning, and I believe that you get better at it as you build more models and practice using several parameter values.
Communicating Model Results
After building and evaluating the model, you need to communicate the model results and present your findings to stakeholders. Based on my experience, I've discovered that top management executives aren't interested in the fancy algorithm you used to build the model or the number of hyperparameters used. They're mainly interested in understanding what they can do with your model and how it will drive their business forward.
As such, every data scientist needs to have good presentation and data storytelling skills to show how a model helps address the business problems identified in the first phase of the life cycle. Using sophisticated wording and putting complex formulas on your presentation slide won't get you far. But by showing your model's real value in a precise and concise way, it becomes easier for the executives to adopt the model.
Model Deployment and Maintenance
Communication is usually not the last phase in the data science project lifecycle. Once the stakeholders are pleased with your model's results, the next step is to deploy the model. A machine learning model isn't built to reside on a local machine forever. It needs to generate value for organizations, and the only way to use the model to make practical, data-driven decisions is by delivering it to end-users. I like the way Luigi Patruno puts it in this article -" no machine learning model is useful unless it's deployed to production".
I don't really fancy the model deployment process because of how cumbersome it can become sometimes. Besides, it involves many back-and-forths between data scientists, business professionals, software engineers, and IT teams. The last thing I'll mention in this section is model maintenance. When I first got into data science, I always thought that a data scientist can just build a model, deploy it and then relax while the model keeps working forever. But, it wasn't long before I discovered that just like machines need maintenance, machine learning models need to be maintained as well.
The "deploy once and run forever" practice is bad because several factors could affect an ML model's predictive power over time. The Covid-19 pandemic is one good example of those unpredictable factors. I'd expect that all organizations have updated or are already planning to update all the ML models they built before the pandemic to capture the new customer patterns and behaviours exposed during the pandemic. Generally, every organization should have a model upgrade strategy for constantly updating their data and retraining their ML model - may be at 3, 6 or 9 months intervals.
Summary
In this post, I was able to explain what data science means. Afterwards, I went ahead to describe the different stages of a data science project lifecycle, including business problem understanding, data collection, data cleaning and processing, exploratory data analysis, model building and evaluation, model communication, model deployment and evaluation.
I assume that you now understand how data science works and the steps you need to build a data science model. If you have further questions or need some more clarifications, please don't hesitate to drop your comments below. In my subsequent posts, I'll discuss the different data science roles in the industry and the skills you need to become a top-notch data scientist.
Thanks for reading. You can share the post with your friends and network as well.